前言 就在十几年前,计算机的储存空间对于普通消费用户来说还是一个相对稀缺的资源。还记得当年家里购买的第一台台式机,它一整台机器满打满算不过只有40多GB的空间,而去除XP系统后,空间更是所剩无几。因此,对于当年的我来说,像“暗黑破坏神2”这种占用空间高达1.1GB的游戏就已经十分令人震撼了。
随着这些年的硬件迭代,用户的储存需求也高速增长着,如今,我们买的一台新电脑如果没个TB级的储存空间,仿佛都不好意思和人打招呼。当然,这并不仅仅是参数的好看与否的问题,更重要的是,每个人所需的存储空间的确是指数级的上升了。比如随便下载一个3A水准的游戏、随便下载一个蓝光电影、或随便装点软件,所需的容量就要50+GB了。
对于普通用户尚且如此,那就更不用说企业级的数据储存需求了。事实上,对于企业、或是数据中心来说,TB都算不上是基本单位。在数据中心中,EB这样的夸张单位其实也就是属于基本操作。
好了,意识流的废话就先说这么多了,总而言之,在这个所谓的“大数据”的时代,过去的存储计算结构,比如将所有数据放在一台服务器上进行存储、运算,显然已经无法胜任当前的需求。这种背景下,便出现了各类与“大数据”相关的技术,以更高效地解决分布式计算的各种需求。为了追赶一下时代的步伐,本学渣也在这一学期选了“大数据建模与分析”这门课,而一如既往,为了防止课程内容量超出本人微薄的脑容量,我在这里开一篇笔记博文,以备未来不时之需。
目前课程还未结束,本文会随着课程进度,同步更新。
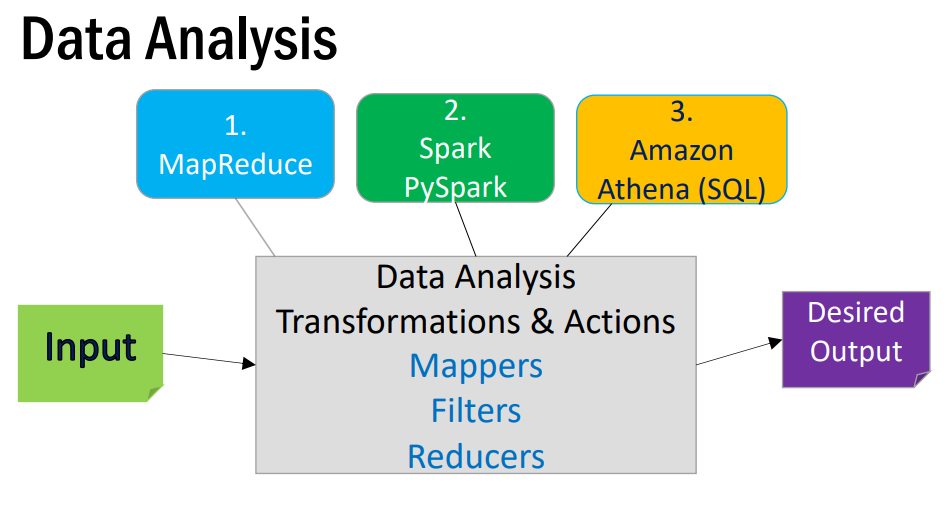
概述 简而言之,这门课程主要只学习三大块内容:大数据分析核心“MapReduce”、MapReduce的新一代实现Spark以及Python环境下的PySpark、最后是云存储Amazon Athena (SQL)。
映射规约-MapReduce 大数据分析中,最基础的部分被称为“MapReduce”。那么什么是“MapReduce”呢?官方一点的说法是一种软件架构,但对我而言,这就是一套标准化的工作流程范式,最初,谷歌在它发表的一篇论文中对其进行了描述。当然,谷歌并没有好心到把它内部使用的MapReduce源代码放出,而仅仅是从宏观层面“描述”了整个流程。当然只看宏观描述就能复现实验的大佬总是存在的,于是在这篇论文后,Hadoop团队利用Java实现了MapReduce并进行了开源,得以让大众从代码层面可以使用这一套流程,因此当我们说到MapReduce时,大多指的就是Hadoop团队实现的这一套开源代码。
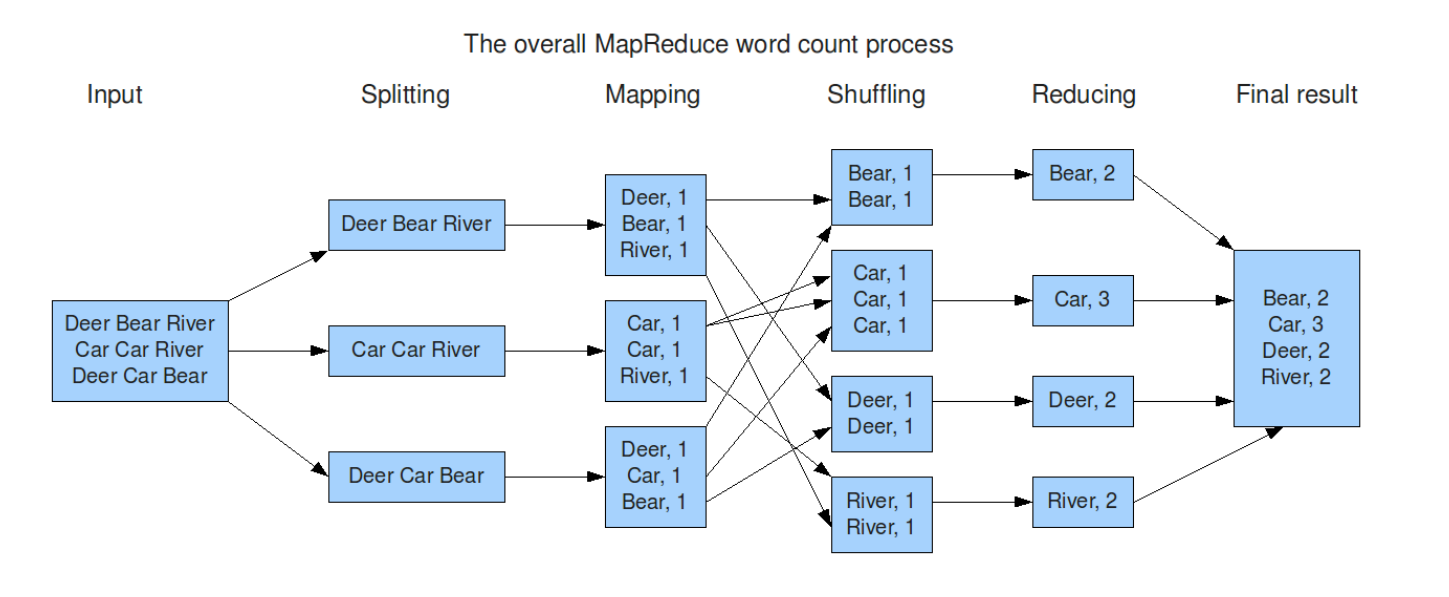
见名知意,MapReduce是“Map”和“Reduce”两词的和,也就是说,这一工作流程被分为映射Map和规约Reduce。在Map阶段之前,首先我们会将要处理的文件拆分,然后分发给不同的子节点机器,每个机器便会按照Map中我们自定义的方法对数据进行处理并输出结果。而Reduce阶段则将前面的结果进行汇总,最终得到我们想要的数据。
当然,由于MapReduce是在业界进化出来的模式,自带反直觉性,也就是说,我们正常人一般来说是不会按它那套模式思考问题的,这就导致了这些描述性的文字对我们而言其实没有实感。所以我就不在这多写了,直接上案例,多做几个案例就能大概明白这一套玩法了。
案例—-词频统计 词频统计属于是MapReduce的入门案例。
需求很直观:统计一份文档中每个词出现的频次。
我们最直观的想法,当然是遍历文档中每一个词,然后将其放到哈希表中。当然,这种方法最大问题就是耗时长,且对于超出机器内存大小的文件无法处理。
而MapReduce则将过程分为“Map”和“Reduce”,在map阶段,将原数据处理为许多(word, 1)的格式,在reduce阶段,则将这些键值对整理为(word, count)的结果输出。
Spark Spark是Apache下的大数据处理引擎,其建立在“弹性分布式数据集”(Resilient Distributed Dataset)之上,当然我们一般将这个数据集简称为“RDD”
这里不去讨论RDD的具体实现,也不过多探讨Spark的底层原理,简介可以在 这里 看到。总而言之,相较于之前的Hadoop MapReduce,Spark的中间数据都是储存在内存层面,而不是硬盘,因此其速度较Hadoop MapReduce要快许多。也就是说Spark是Hadoop MapReduce的继任者。
PySpark Spark起初是写在Java语言之上,然而,由于Python相较java而言,对于大部分用户来说更简单易用,Spark也对于Python进行了适配,而这就是PySpark。
当我们在Python平台下使用Spark,由于其弱类语言的特性,我们无需考虑返回值的类型之类的东西,开发极其简单。可以说PySpark将大数据的门槛极大的拉低。
SparkContext对象 使用Spark时,我们首先要获取一个SparkContext对象来进行初始化。
RDD算子们 Spark处理大数据,其实和SQL很像,我们作为开发者,代码无需过多关注集群机器之间的交互,在开发时,只要使用RDD的算子,Spark会在运行时自动调度集群资源。只要当成是在同一台机器上运行进行开发即可。
RDD算子有很多,这里不一一阐述,就用一次作业来作为案例。
需求:我们现在有一份电影评分数据,格式为:<用户名user_id><,><电影名movie_id><,><评分rating>。我们想得到的结果有:
每个电影的平均分数,输出为:[movie_id_1] [average-rating-for-movie_id_1]
获得到5分的电影列表,输出为:[“rating-5”] [list-of-unique_movies-rated-as-5]
做法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 from pyspark import SparkContextsc = SparkContext('local' , 'test' ) raw_rdd = sc.textFile("movies.txt" ) filtered_rdd = raw_rdd \ .map (lambda x: x.split(',' )) \ .filter (lambda x: (len (x)==3 ) and (x[2 ]>='2' )) mapped_rdd = filtered_rdd \ .map (lambda x: (x[1 ], ord (x[2 ])-48 )) mapped_rdd.cache() average_rdd = mapped_rdd.mapValues(lambda v: (v, 1 )) \ .reduceByKey(lambda a,b: (a[0 ]+b[0 ], a[1 ]+b[1 ])) \ .mapValues(lambda v: v[0 ]/v[1 ]) \ .filter (lambda x: x[1 ]>=2.5 ) rate_five_rdd = mapped_rdd.filter (lambda x: x[1 ]==5 ) \ .map (lambda x: ("rating-5" , x[0 ])) \ .distinct() \ .groupByKey() \ .map (lambda x: (x[0 ], list (x[1 ]))) rate_five_rdd.cache() average_rdd.cache() mapped_rdd.unpersist() result_rdd = average_rdd.union(rate_five_rdd) result_rdd.saveAsTextFile("result" )
还有一个作业,这里用到了csv文件,其实更好的做法是放在下文讲的PySpark SQL中来做,但这里还是先采用RDD算子的方式,以增加熟练度。
需求:我们现在有一份白宫的访客数据。我们想得到的有:
前十的访客名单,输出为:[visitor] [frequency],其中[visitor]中为(NAMELAST, NAMEFIRST)
前十的受访者名单,输出为:[visitor] [frequency],其中[visitor]中为(visitee_namelast, visitee_namefirst)
前十的访客-受访者列表,输出为:[visitor][-][visitee] [frequency]
丢弃(无效)的数据数,无效的判定标准为:NAMELAST或visitee_namelast为空
做法如下:
1 2 wget https://obamawhitehouse.archives.gov/sites/default/files/disclosures/whitehouse_waves-2016_12.csv_.zip
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 import zipfilewith zipfile.ZipFile("whitehouse_waves-2016_12.csv_.zip" , "r" ) as zip_ref: zip_ref.extractall() from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("white-house-log" ).getOrCreate() sc = spark.sparkContext records_raw_rdd = sc.textFile("whitehouse_waves-2016_12.csv" ) header = records_raw_rdd.first() recordsNoHeader_raw_rdd = records_raw_rdd.filter (lambda row: row != header) header_list = header.split("," ) broadcast = sc.broadcast(header_list) acmlt = sc.accumulator(1 ) def filter_function (line ): if (line[broadcast.value.index('NAMELAST' )] == "" or line[broadcast.value.index('visitee_namelast' )] == "" ): global acmlt acmlt += 1 return False else : return True filtered_rdd = recordsNoHeader_raw_rdd\ .map (lambda line: line.split("," ))\ .filter (filter_function) filtered_rdd.cache() vistor_rdd = filtered_rdd\ .map (lambda line: ((line[broadcast.value.index('NAMELAST' )].upper(), line[broadcast.value.index('NAMEFIRST' )].upper()), 1 ))\ .reduceByKey(lambda x, y: x + y)\ .sortBy(lambda x: x[1 ], False ) vistor_rdd.cache() vistee_rdd = filtered_rdd\ .map (lambda line: ((line[broadcast.value.index('visitee_namelast' )].upper(), line[broadcast.value.index('visitee_namefirst' )].upper()), 1 ))\ .reduceByKey(lambda x, y: x + y)\ .sortBy(lambda x: x[1 ], False ) vistee_rdd.cache() vistor_to_vistee_rdd = filtered_rdd\ .map (lambda line: ("<" +line[broadcast.value.index('NAMELAST' )].upper() + "_" +\ line[broadcast.value.index('NAMEFIRST' )].upper() + "> - <" +\ line[broadcast.value.index('visitee_namelast' )].upper() + "_" +\ line[broadcast.value.index('visitee_namefirst' )].upper()+">" , 1 ))\ .reduceByKey(lambda x, y: x + y)\ .sortBy(lambda x: x[1 ], False ) vistor_to_vistee_rdd.cache()
PySpark SQL 要进行数据处理、分析,除了上述的文本文档格式外,处理结构化数据SQL是无法绕开的一环,毕竟大部分学大数据的人,本质是要给企业打工的,而在企业中,数据一般都是存储在数据库中。
对于SQL来说,Spark也支持直接对数据库进行访问,并可以SQL语句与代码混合运行,很方便。
SparkSQL中,数据存储在一种叫DataFrame的类中,当然这与Pandas的DataFrame并不是一个东西,不过他们两个的实现十分相似,不同点是Spark的数据表存储在分布式集合之中,而非本机。
当然,对于Jvm的开发,SparkSQL使用的数据抽象则是DataSet,其带有泛型特性,这里我们主要不讨论这个,因为python不支持泛型。
那么DataFrame与之前的RDD有什么区别?主要是在于其存储的数据结构不同,RDD中什么都可以存,而DataFrame则仅存二维结构化数据(其实就是我们常见的表格)。
SparkSession对象 在之前的使用中,我们通过SparkContext来获取初始化,而在SparkSQL中,我们则是用更新的SparkSession来创建初始化对象。
1 2 3 4 5 6 7 8 spark = SparkSession.builder.\ appName("test" ).\ master("local[*]" ).\ getOrCreate() sc = spark.sparkContext
之前的白宫访客问题,也可以使用DataFrame来处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 from pyspark.sql import SparkSessionimport pyspark.sql.functions as fspark = SparkSession.builder.appName("white-house-log" ).getOrCreate() import zipfilewith zipfile.ZipFile("whitehouse_waves-2016_12.csv_.zip" , "r" ) as zip_ref: zip_ref.extractall() df = spark.read.option("header" , "true" ).csv("whitehouse_waves-2016_12.csv" ) df_visitor_n_visitee = df["namelast" , "namefirst" , "visitee_namelast" , "visitee_namefirst" ] \ .na.drop(subset=["namelast" , "visitee_namelast" ]) \ .toDF(*[c.lower() for c in ["namelast" , "namefirst" , "visitee_namelast" , "visitee_namefirst" ]]) \ .withColumn('namelast' , f.lower(f.col('namelast' ))) \ .withColumn('namefirst' , f.lower(f.col('namefirst' ))) \ .withColumn('visitee_namelast' , f.lower(f.col('visitee_namelast' ))) \ .withColumn('visitee_namefirst' , f.lower(f.col('visitee_namefirst' ))) \ .select(f.concat_ws('_' ,"namelast" ,"namefirst" ).alias("visitor" ), f.concat_ws('_' ,"visitee_namelast" ,"visitee_namefirst" ).alias("visitee" )) \ .select("visitor" , "visitee" , f.concat_ws(' - ' ,"visitor" ,"visitee" ).alias("visitor-visitee" )) df_visitor_count = df_visitor_n_visitee.groupBy("visitor" ) \ .count() \ .sort("count" , ascending=False ) \ .limit(10 ) df_visitee_count = df_visitor_n_visitee.groupBy("visitee" ) \ .count() \ .sort("count" , ascending=False ) \ .limit(10 ) df_visitor_n_visitee_count = df_visitor_n_visitee.groupBy("visitor-visitee" ) \ .count() \ .sort("count" , ascending=False ) \ .limit(10 ) dropped_count = df.count() - df_visitor_n_visitee.count() print ("The 10 most frequent visitors to the White House are:" )df_visitor_count.show() print ("The 10 most frequently visited people in the White House are:" )df_visitee_count.show() print ("The 10 most frequent visitor-visitee combinations are:" )df_visitor_n_visitee_count.show() print (f"The number of records dropped is: {dropped_count} " )
利用不同API风格进行开发 pyspark sql 可以使用两种风格:SQL风格或DSL风格
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 df = spark.read.csv(xxx.csv) df2 = df.toDF("id" , "name" , "score" ) df2.printSchema() df2.show() df2.createTempView("score" ) spark.sql(""" SELECT * FROM score WHERE name='aa' LIMIT 5 """ ).show()df2.where("name='aa'" ).limit(5 ).show()
当然,pyspark的API还有很多很多,使用时查文档即可,这里就不多赘述了。
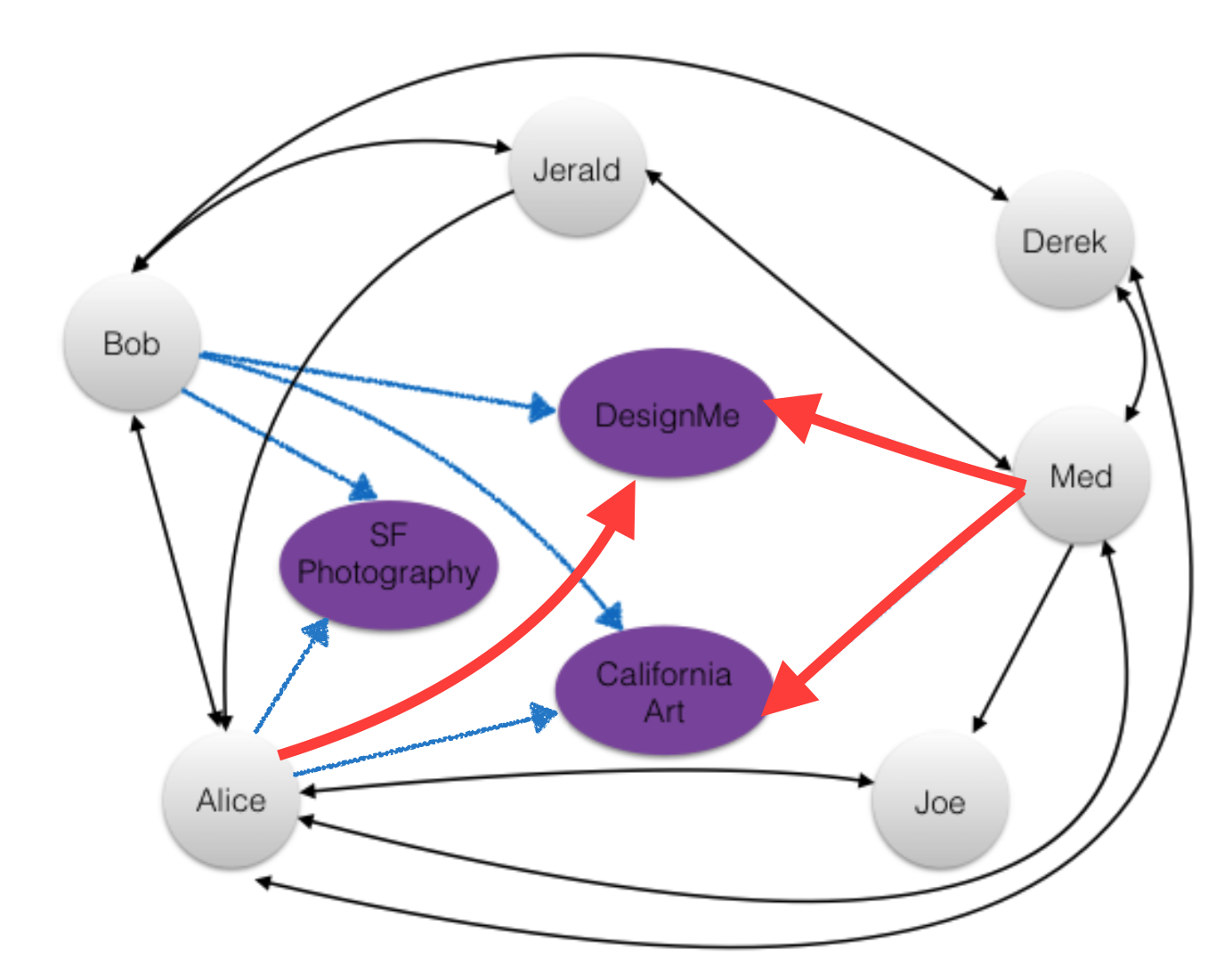
GraphFrames 简介 除了上述的结构化表数据外,还有一种数据结构会在很多地方用到:图Graph。
Graph简而言之就是用来描述关系的一类数据,如下图:
而Spark原生并未对图数据定义相应的数据抽象,为了对图进行处理,社区大佬们制作了GraphFrames这一插件,以便对图进行计算。
配置 Python 环境使用 GraphFrames 如果pySpark代码里用到了GraphFrame,则需要在提交程序文件时让spark加载相应版本的GraphFrame插件:
1 spark-submit --packages graphframes:graphframes:0.8.0-spark3.0-s_2.12 xxxx.py
Jupyter 环境使用 GraphFrames 很多时候我们希望用jupyter来进行程序的调试,然而GraphFrame并不能安装到python环境中,因此运行import时会提示无法找到GraphFrame包。为了解决这一问题,我们需要在启动pyspark时开启一个包含了GraphFrame的jupyter的服务器。
只需要在环境变量中添加两个变量即可:
1 2 export PYSPARK_DRIVER_PYTHON=jupyterexport PYSPARK_DRIVER_PYTHON_OPTS=notebook
运行下述指令:
1 pyspark --packages graphframes:graphframes:0.8.0-spark3.0-s_2.12 --jars graphframes-0.8.0-spark3.0-s_2.12.jar
如果不加之前的环境变量,此时会直接进入pyspark环境,然而添加环境变量后,便会开启一个jupyter服务器,按提示连接便可。
这里要提一句,该方法只有在本地环境才能使用,如果你在用Colab一类的远程环境,就没法用GraphFrame了。
Motif Find 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from graphframes import *from pyspark import *from pyspark.sql import *import pyspark.sql.functions as fimport sysinput_path = sys.argv[1 ] spark = SparkSession.builder.master("local[*]" ).appName('fun' ).getOrCreate() sc = spark.sparkContext records_raw_rdd = sc.textFile(input_path) edges = records_raw_rdd\ .map (lambda x: x.split("," ))\ .toDF(['src' , 'dst' , 'type' ]) vertices = records_raw_rdd\ .map (lambda x: x.split("," ))\ .flatMap(lambda x: [x[0 ], x[1 ]])\ .distinct()\ .map (lambda x: [x])\ .toDF(['id' ]) graph = GraphFrame(vertices, edges) motifs = graph.find("(a)-[]->(b); (b)-[]->(c); (c)-[]->(a)" ) motifs[(motifs.a<motifs.b) & (motifs.b<motifs.c)].show()
Amazon Athena 简介 没啥高深的,就是一个文件服务器,用户可以用SQL语句访问。
使用 买了参考文档即可,要花钱,本人就没有很深入的研究。
后记
**未完待续...**